前言
虽然Hadoop是用Java编写的一个框架, 但是并不意味着他只能使用Java语言来操作, 在Hadoop-0.14.1版本后, Hadoop支持了Python和C++语言, 在Hadoop的文档中也表示可以使用Python进行开发, 通常来说都会考虑将源码打包成jar包再运行, 例子: PythonWordCount 这明显不方便. 在Hadoop的文档中提到了Hadoop Streaming, 我们可以使用流的方式来操作它.
它的语法是
hadoop jar hadoop-streaming-2.9.2.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /usr/bin/wc
指定输入输出文件和mapper, reducer即可.
在Python中的sys包中存在, stdin和stdout,输入输出流, 我们可以利用这个方式来进行MapReduce的编写. 本文以WordCount进行举例
Coding
我们在工程目录下创建两个文件,分别是mapper.py和reducer.py, 之后使用命令chmod +x mapper.py来给他们赋予执行权限.
Mapper
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
-------------------------------
FileName: mapper
Author: ying
Date: 18-12-6
-------------------------------
Change Activity: 18-12-6
"""
import sys
__author__ = "YingJoy"
for line in sys.stdin:
# 捕获输入流
line = line.strip()
words = line.split()
for word in words:
# 注意这里哦
print("%s\t%s" % (word, 1))
Reducer
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
-------------------------------
FileName: reducer
Author: ying
Date: 18-12-6
-------------------------------
Change Activity: 18-12-6
"""
import sys
__author__ = "YingJoy"
word_dict = {}
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t')
try:
count = int(count)
except ValueError:
continue
if word in word_dict:
word_dict[word] += 1
else:
word_dict.setdefault(word, 1)
for k, v in word_dict.items():
print('%s\t%s' % (k, v))
测试代码
这里使用Linux的管道来进行测试, 将前一项的输出作为后一项的输入
echo "foo foo quux labs foo bar quux" | ./mapper.py
`
foo 1
foo 1
quux 1
labs 1
foo 1
bar 1
quux 1
`
echo "foo foo quux labs foo bar quux" | ./mapper.py | sort -k1,1 | ./reducer.py
`
bar 1
foo 3
labs 1
quux 2
`
在Hadoop上运行代码
准备
首先我们在http://www.gutenberg.org/这个网站上随便下基本电子书(选择Plain Text UTF-8)
然后使用命令将文本上传到HDFS中
# 创建文件夹, 否则出错
hdfs dfs -mkdir gutenberg
hdfs dfs -put *.txt gutenberg
hdfs dfs -ls gutenberg
这里说明一下, HDFS的相对目录, 是相对于当前用户的目录, 如我的用户是ying, 它默认的位置就是/user/ying
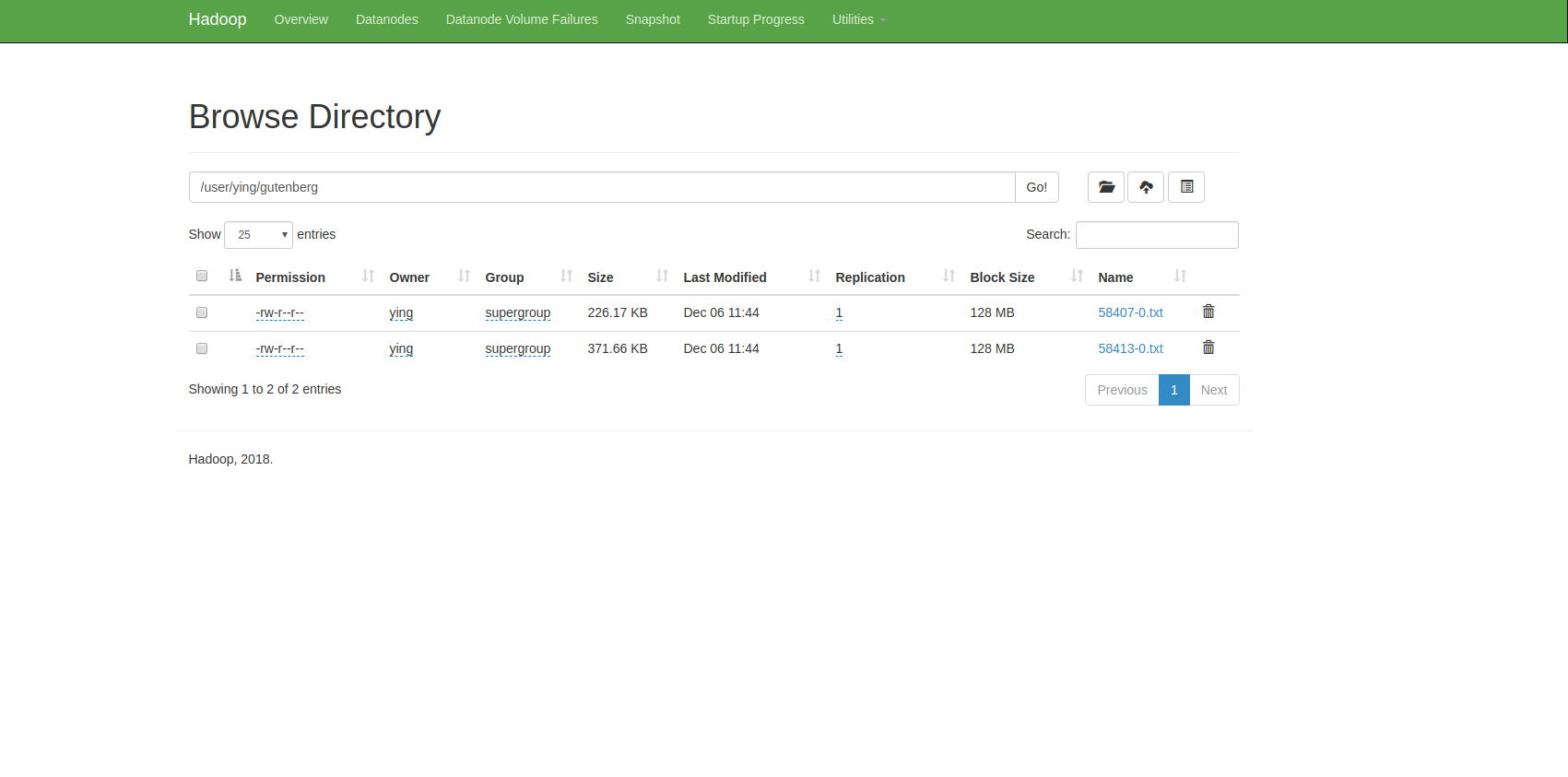
然后你就可以在HDFS看到刚刚上传的文件了
启动MapReduce任务
运行下面的命令
hadoop jar /opt/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar -file ./mapper.py -mapper ./mapper.py -file ./reducer.py -reducer ./reducer.py -input /user/ying/gutenberg/* -output /user/ying/output
注意,这里使用的hadoop命令, 如果你使用hdfs命令会报错误: 找不到主类
运行之后你可以在本地: localhost:8088 看到你的任务, 如图


等待任务完成即可在输出目录下看到结果,注意这里的output目录运行之前不能存在,否则报错