深度学习(神经网络)中许多的想法都已经存在了几十年。为什么今天这些想法火起来了呢?
促进机器学习发展的因素主要有两个:
• 数据量越来越多. 如今人们在数字设备(电脑,移动设备)上所花费的时间相比以前多得多,这些活动产生了大量的数据,我们可以使用这些数据来训练我们的算法。
• 计算能力的提升. 人类几年前才开始训练神经网络,而且这些神经网络都足够大,可以将现在的大数据作为输入。
具体来说,如果你使用的是传统的机器学习算法(如:逻辑回归),即使你拥有更大的数据量,也会出现“高原效应(plateaus)”。也就是说即使你给它更多的数据,它的学习曲线也会变得平坦(flattens out),算法就不会再有很明显的提升了:
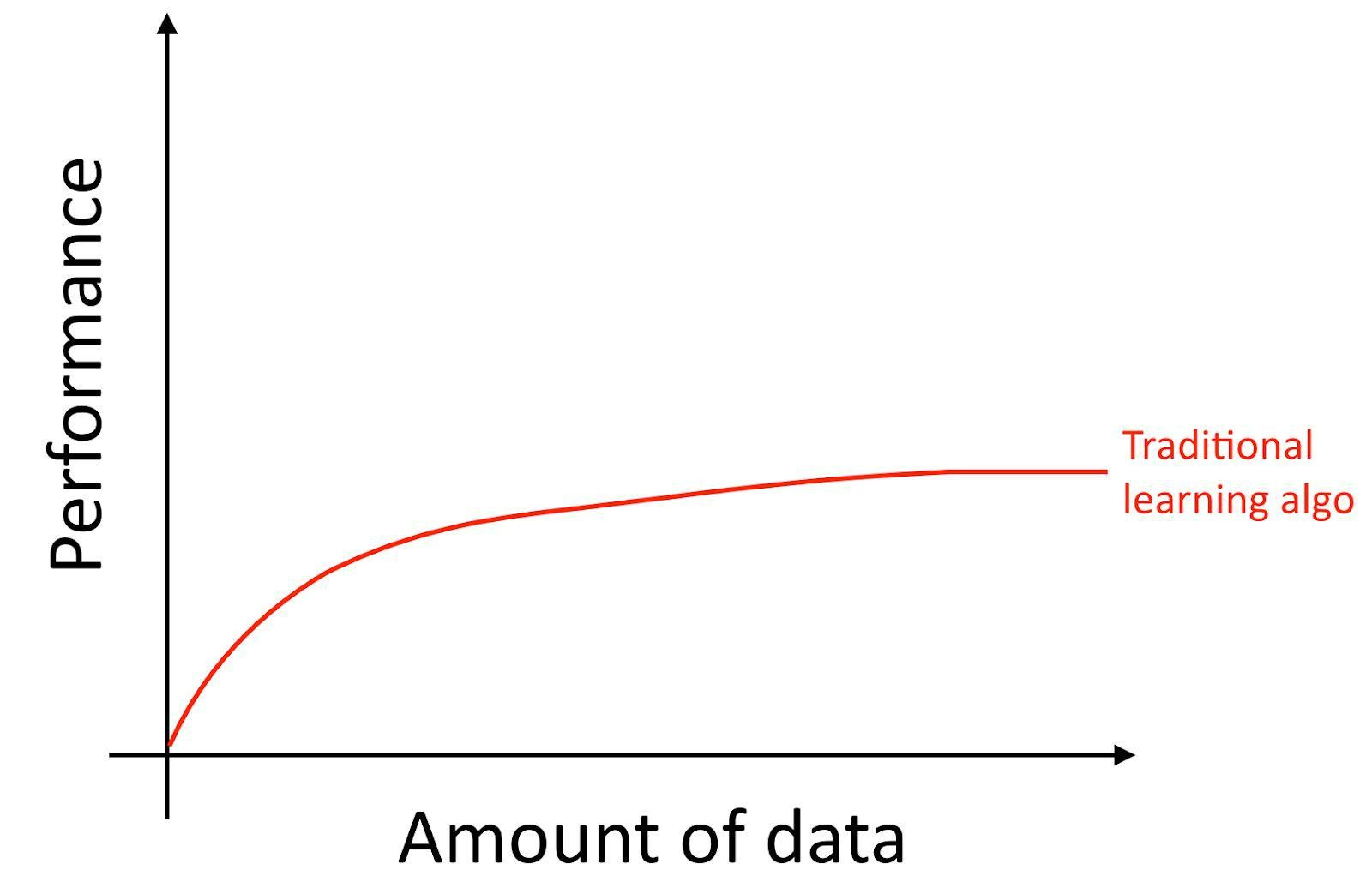
这就好像是传统算法不知道该怎么处理我们所拥有的全部数据。
如果你在面对监督学习任务时训练了一个小型的神经网络,可能你会获得相对较好效果: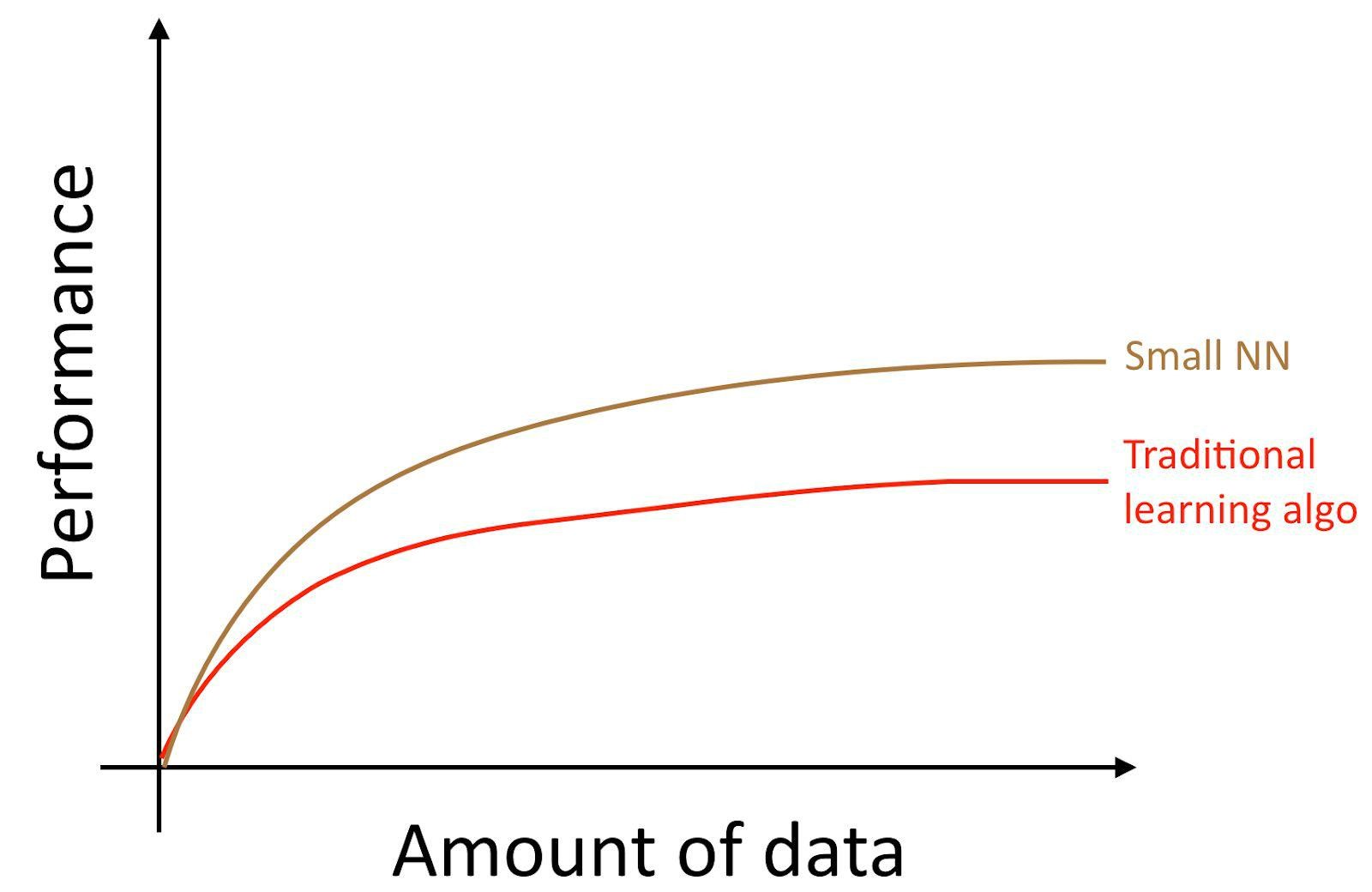
这里,“小型神经网络(small NN)”是指具有较少的隐层神经元/层/参数。你训练的神经网络越大,性能就会越好。[1]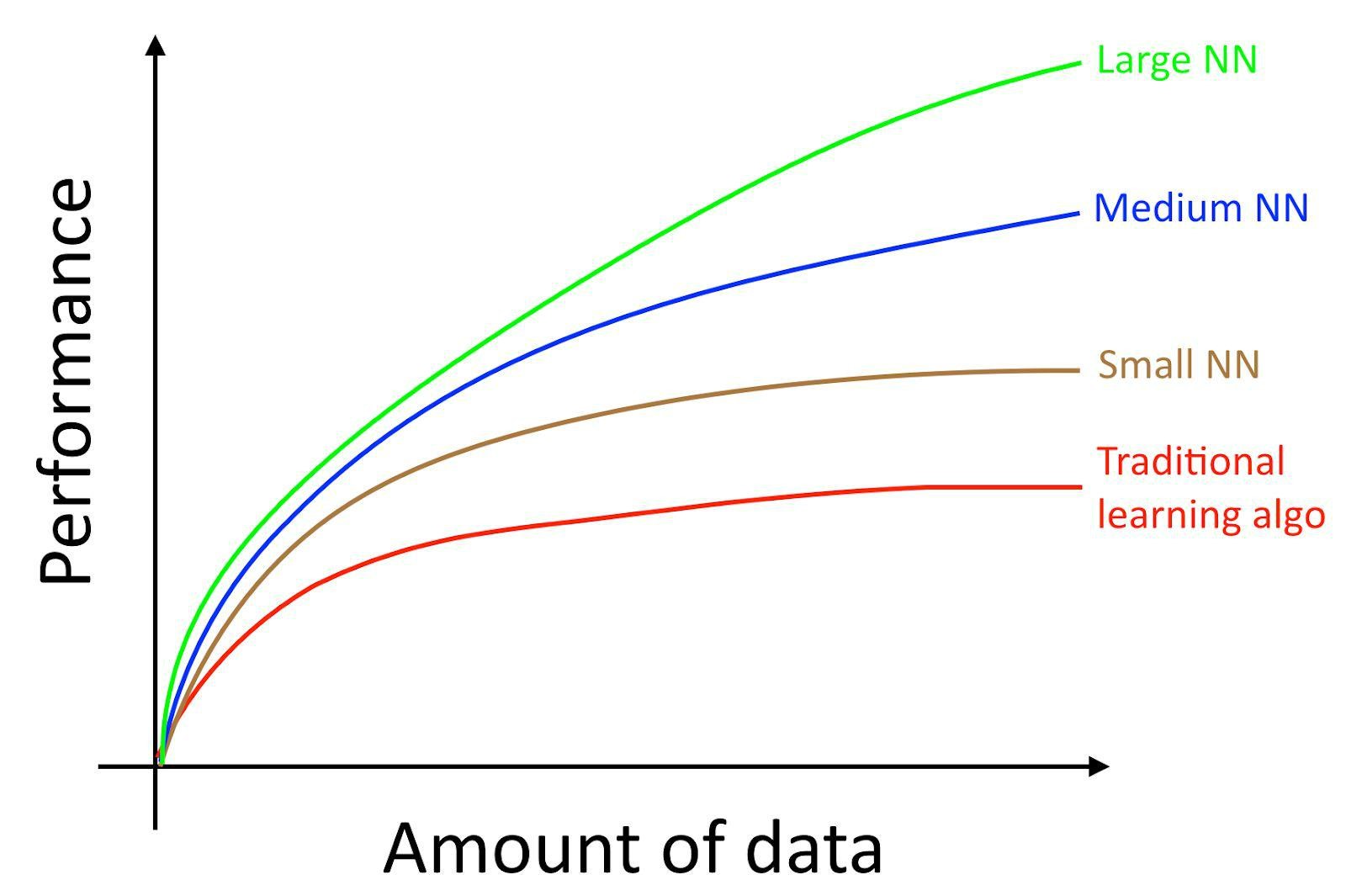
因此,如果你想获得较好的性能,你需要:
(1)训练一个较大的神经网络。
(2)拥有大量的数据。
还有很多其它的细节也是非常重要的,如神经网络的架构,在这方面的创新目前也是非常多的。但是想提高你算法的性能最可靠的方法还是:
(1)训练一个较大的神经网络。
(2)拥有大量的数据。
[1] 这个图展示了神经网络在数量较少的数据集上也能有不错的效果(前半部分)。神经网络在大数据中展现的效果很好,但是在小数据集上就不一定了。在小数据集中,可能传统算法会做的更好,这取决于特征的选择。比如,你只有20个训练样本,那么你使用logistic regression或神经网络可能没有什么区别,主要是特征的选择对算法结果造成的影响较大。但是,如果你拥有100万的数据量,那我更倾向使用神经网络。