你的团队有以下几个想法,来改进你的猫咪分类器:
• 解决狗被错误分为猫咪的问题。
• 解决“大型猫科动物(greast cats)”(狮子或豹子等)被错认家猫(宠物)的问题
• 提高系统在模糊(Blurry)图像上的表现
• …
你可以并行并且有效的评估这些想法。我通常会创建一个表格,查看100个分类错误的开发集样本并记录在表格上,同时进行注释。用有小开发集里的4个错误分类样本来说明这个过程,你的表格大概将会是下面的样子:
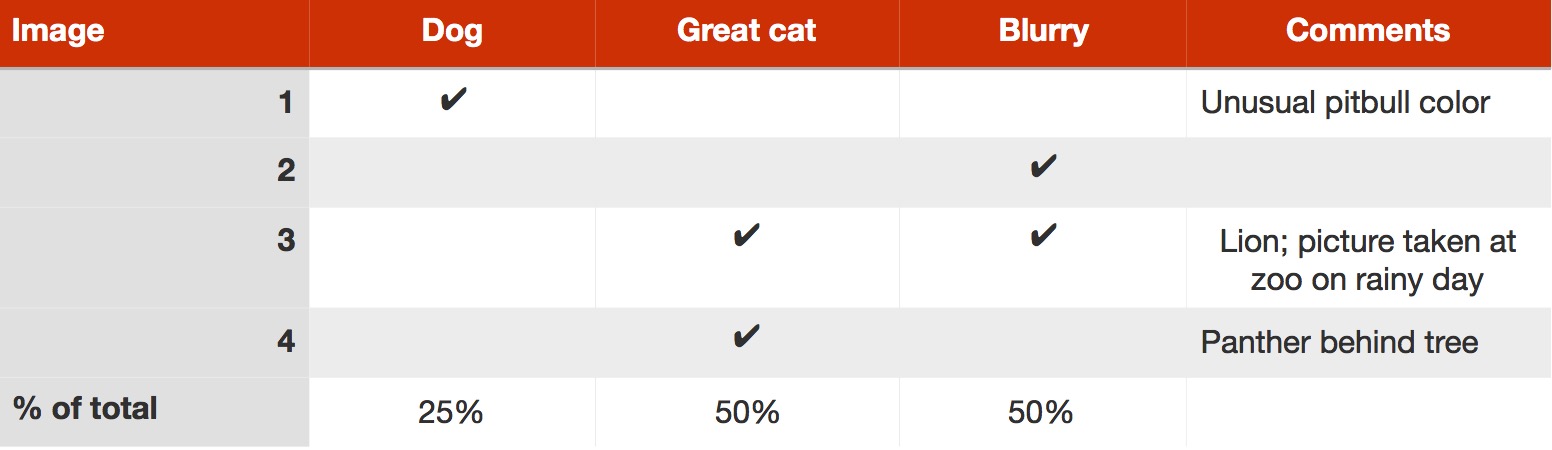
表格中Image3的Great cat和Blurry列都被勾选了:可以将一个样本与多个类别相关联, 这就是为什么最后的百分比加起来不足100%的原因。 虽然我已经将这个过程首先描述为类别分类(Dog, Great cat, Blurry), 然后查看样例对他们进行分类。实际中,当你查看样例时,可能会受到启发,然后提出一些新的错误类别。例如,当你查看过十几张图像后,你发现许多错误都经过Instagram(一款美图软件)的滤镜处理。你可以在表格中添加一列Instagram,看看图像是否被滤镜处理过。手动查看算法出错的样例,并思考正常人是如何将这些样例正确分类的。这通常会启发你提出新的类别和解决办法。
你的想法对于改进错误类别是非常有用的。例如:如果你没办法将经过Instagram处理的图像还原的话,那么添加Instagram类别是最好的办法。但是你不必局限于你已经有想法去解决这个问题;这个过程主要目的是帮助你找到你认为最值得关注的问题。 错误分析是一个迭代的过程。开始的时候在你脑海中可以没有任何分类。通过查看图片,你可能会提出一些关于错误类别的想法。然后手动分类一些错误图片以后,可能会启发你想出一些新的错误类别,根据新的类别在返回重新检查这些图片,以此类推。 假设你完成了100个错误分类的开发集样本,得到如下表格:
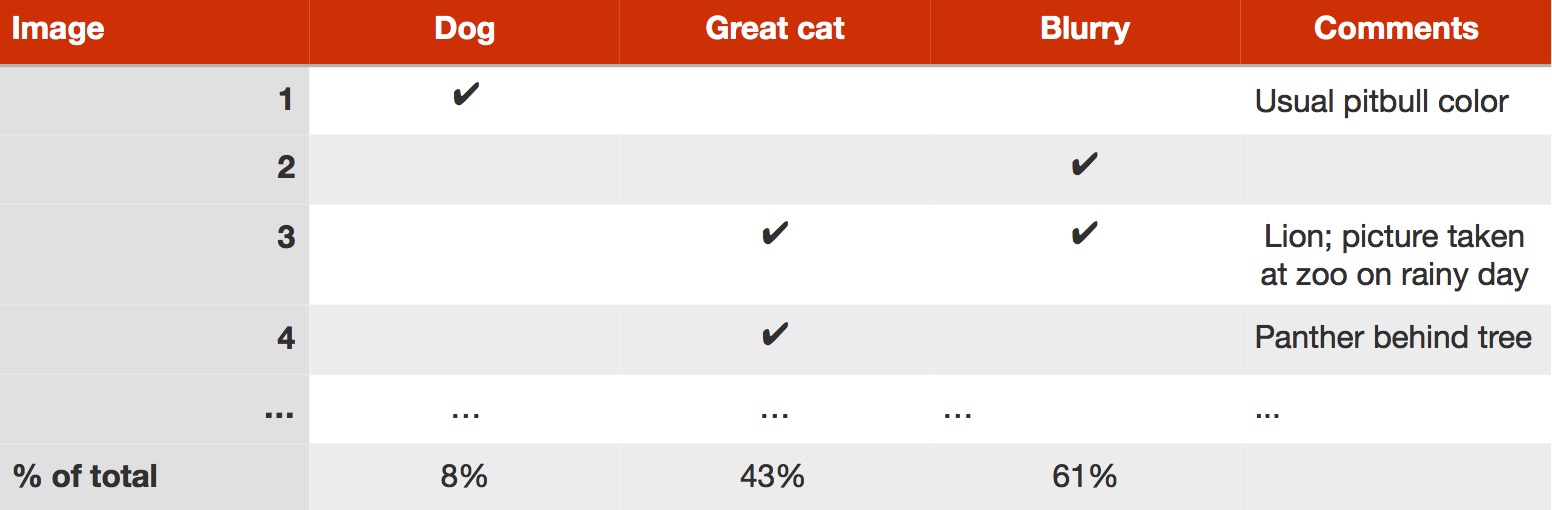
你现在知道解决狗分类错误的问题,最多可以消除8%的误差。而致力于Great cat和Blurry对你的帮助更大。因此,你可能会挑选后者之一来进行处理。如果你的团队有足够多的人可以同时展开多个方向,你让一部分人解决Great cat问题,另一部分人解决Blurry问题。 错误分析并不会得出一个明确的数学公式来告诉你最应该先处理哪个问题。你还必须考虑在不同错误类别上取得的进展,以及每个错误类别所需的工作量。