1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| def getProbWord(self, testDict, normalDict, spamDict, numNormal, numSpam):
"""
计算对分类结果影响最大的15个词
:param testDict: 测试数据字典
:param normalDict: 正常邮件字典
:param spamDict: 垃圾邮件字典
:param numNormal: 正常邮件的数量
:param numSpam: 垃圾邮件的数量
:return wordProbList: 对分类结果影响最大的15个词
"""
wordProbList = {}
for word, num in testDict.items():
if word in spamDict.keys() and word in normalDict.keys():
pw_n = normalDict[word] / numNormal
pw_s = spamDict[word] / numSpam
ps_w = pw_s / (pw_s + pw_n)
wordProbList[word] = ps_w
if word in spamDict.keys() and word not in normalDict.keys():
pw_s = spamDict[word] / numSpam
pw_n = 0.01
ps_w = pw_s / (pw_s + pw_n)
wordProbList[word] = ps_w
if word not in spamDict.keys() and word in normalDict.keys():
pw_s = 0.01
pw_n = normalDict[word] / numNormal
ps_w = pw_s / (pw_s + pw_n)
wordProbList[word] = ps_w
if word not in spamDict.keys() and word not in normalDict.keys():
wordProbList[word] = 0.5
sorted(wordProbList.items(), key=lambda d: d[1], reverse=True)[0:15]
return wordProbList
def calBayes(self, wordList, spamDict, normalDict):
计算贝叶斯概率
:param wordList: 词表
:param spamDict: 垃圾邮件词语字典
:param normalDict: 正常邮件词语字典
:return: 概率
ps_w = 1
ps_n = 1
with open('wordsProb.txt', 'a', encoding='utf-8') as f:
for word, prob in wordList.items():
f.write(word + : + str(prob) + \n)
ps_w *= prob
ps_n *= 1 - prob
p = ps_w / (ps_w + ps_n)
return p
def calAccuracy(self, testResult):
计算精度
:return:
rightCount = 0
errorCount = 0
for name, catagory in testResult.items():
if (int(name) < 1000 and catagory == 0) or (int(name) > 1000 and catagory == 1):
rightCount += 1
else:
errorCount += 1
return rightCount / (rightCount + errorCount)
|
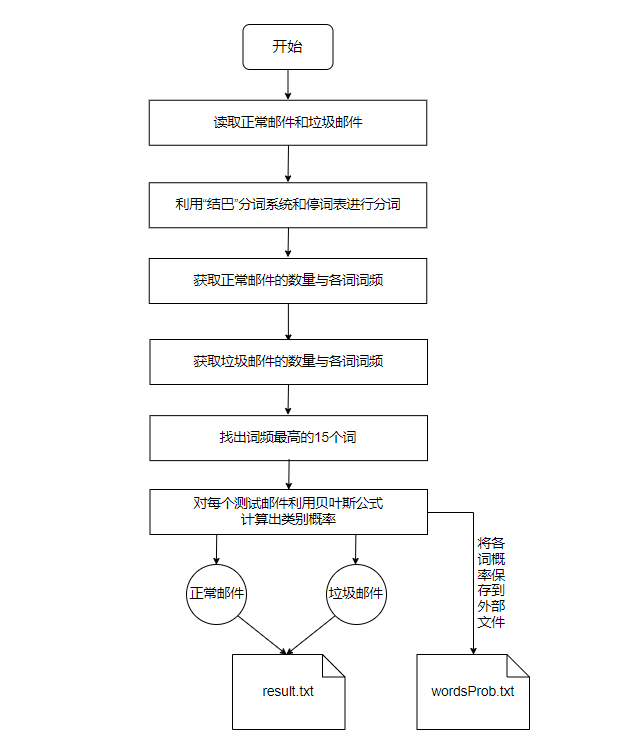 此处将结果输出到result.txt文件中 各词概率保存到wordsProb.txt中 ### Code:
此处将结果输出到result.txt文件中 各词概率保存到wordsProb.txt中 ### Code: