Pandas教程
Pandas是高效的数据读取、处理与分析的Python库,下面将学习Pandas的基本用法
1. 创造对象
导入pandas , numpy, matplotlib库
1 | import pandas as pd |
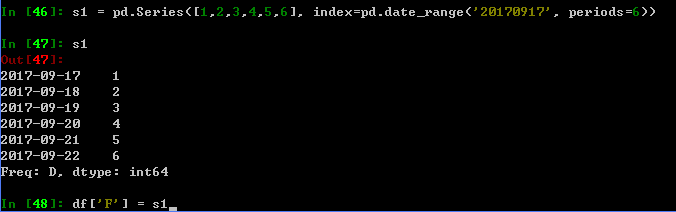
Series是一个值的序列 ,它只有一个列,以及索引,下面的例子中,就是用默认的整数索引
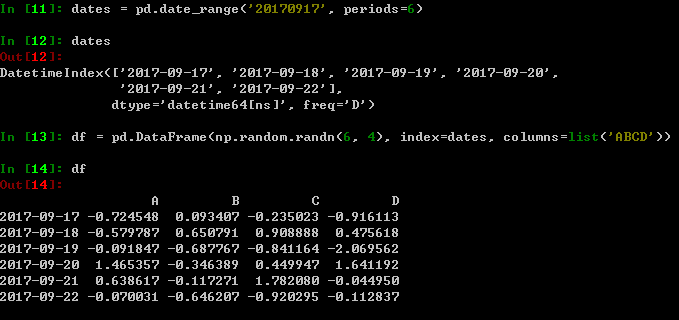
DataFrame是有多个数据表,每个列拥有一个label,DataFrame也拥有索引
如果参数是一个dict(字典),每个dict的value会被转换成一个Series
可以这样理解,DataFrame是由Series组成
2. 查看数据
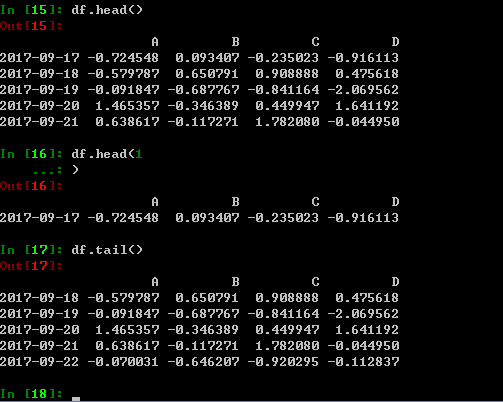
用head和tail查看顶端和底端的几行,head和tail的默认参数是5
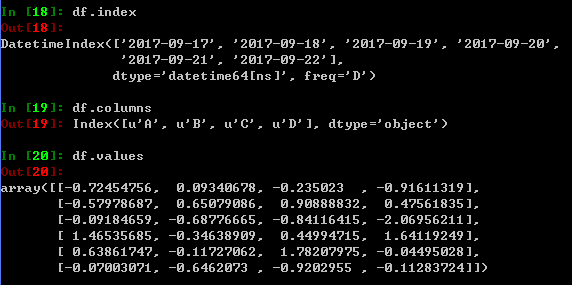
实际上DataFrame内部用numpy 格式存储数据,可以单独查看index和columns
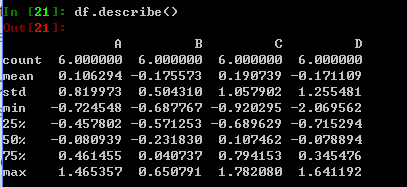
describe()显示数据概要
和numpy一样,可以方便的得到转置

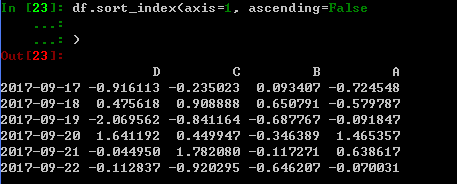
对axis按照index排序(axis=1指第二个纬度,即 列)
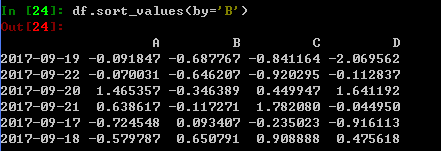
按值排序
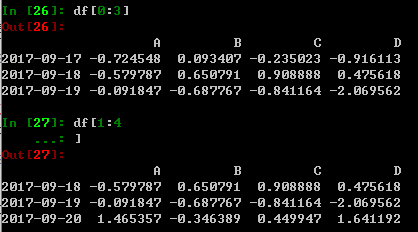
3. 选择行和列
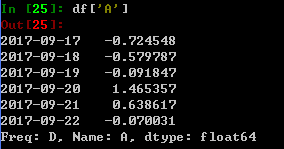
从DataFrame选择一个列,就得到了一个Series
和numpy类似,这里可以使用 []
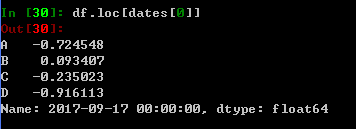
4. 通过label选择
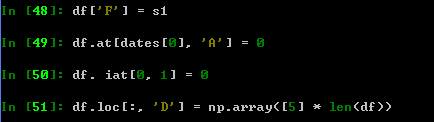
刚刚的DataFrame可以通过时间戳的下标(dates[0]=Timestamp(‘20170917’))来访问
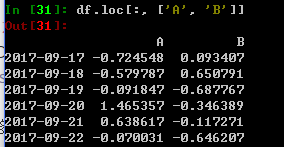
还可以多选
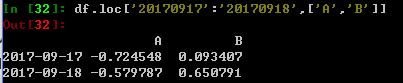
冒号和Matlab或Numpy里面的冒号用法是一样的,也可以加上行
5. 通过整数下标选择
和Matlab完全一样
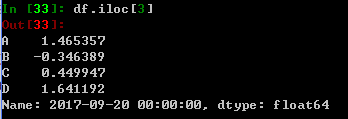
选出34行, 01列
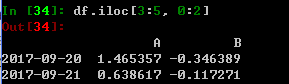
左闭右开
也可以用list选择
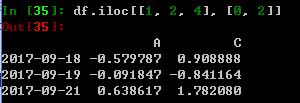
也可以用slice切片
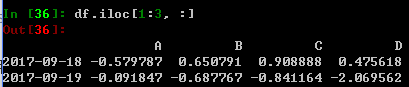
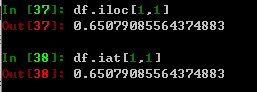
对单个元素
6. 布尔值下标
基本用法
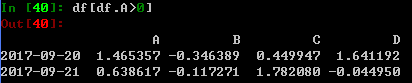
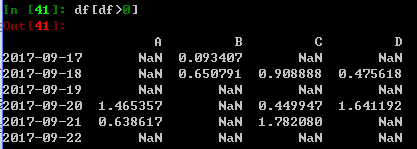
没有填充的值均为NaN
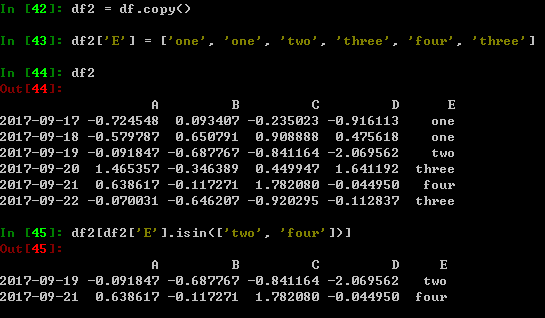
copy()函数:复制DataFrame
isin()函数:是否在集合中,并选出
7. Setting
为DataFrame增加新的列,按index对应
通过label 下标 numpy 布尔值作下标 设置
8. 缺失值
pandas用np.nana表示缺失值,不加入计算
dropna()丢弃有NaN的行fillna(value=5)填充缺失值pd.isnull()获取布尔值的mask,哪些是NaN
9. 统计
平均值 mean()
对另一个纬度做平均值只需加一个参数mean(1) 这里的1是纬度, 0表示x , 1 表示y, 2表示z 以此类推
10. Apply函数
对行或列进行操作,可以用lambda表达式
11. 读取csv xls hdf5
1 | pd.read_csv('filename') |