前言
Apache Hadoop软件库是一个框架,开发者只需使用简单的编程模型在大量计算机(配置不高)上对大型数据集进行分布式处理。

YingJoy
Hadoop有两种安装模式
- 完全分布式
- 伪分布式(单机)
本文采用完全分布式进行安装。
准备
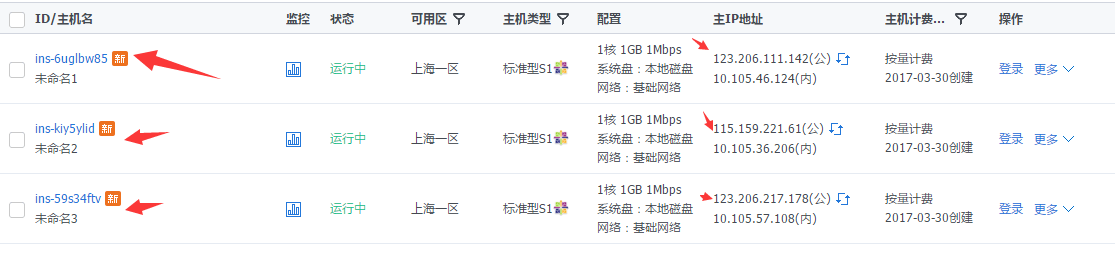
1
2
3
| master: 123.206.111.142 hadoop-master
slave : 115.159.221.61 hadoop-slave-1
slave : 123.206.217.178 hadoop-slave-2
|
一、安装Java
执行下面代码
1
2
3
4
| cd /opt/
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz"
tar xzf jdk-7u79-linux-x64.tar.gz
|
用alternatives安装Java
1
2
3
| cd /opt/jdk1.7.0_79/
alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2
alternatives --config java
|
你会看到这个
1
2
3
4
5
6
7
8
9
| There are 3 programs which provide 'java'.
Selection Command
-----------------------------------------------
* 1 /opt/jdk1.7.0_60/bin/java
+ 2 /opt/jdk1.7.0_72/bin/java
3 /opt/jdk1.7.0_79/bin/java
Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
|
这里选择3
现在设置javac和jar命令
1
2
3
4
| alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2
alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2
alternatives --set jar /opt/jdk1.7.0_79/bin/jar
alternatives --set javac /opt/jdk1.7.0_79/bin/javac
|
查看Java是否安装成功
1
2
3
4
5
| java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
|
配置环境变量
在文件尾部加上下面的代码
1
2
3
| export JAVA_HOME=/opt/jdk1.7.0_79
export JRE_HOME=/opt/jdk1.7.0_79/jre
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
|
二、服务器创建Hadoop账号
执行下面代码
1
2
| useradd hadoop
passwd hadoop
|
会看到下面
1
2
3
4
| Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
|
三、修改/etc/hosts
执行下面代码
在文件下面增加下面三句
1
2
3
| master的ip hadoop-master
slave1的ip hadoop-slave-1
slave2的ip hadoop-slave-2
|
四、设置机器之间ssh免密码登陆
仅在Hadoop用户下免密登陆,我听到很多人说配置后仍需密码,那是因为他们使用了root用户来连接。
1
2
3
4
5
6
7
| su - hadoop
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop-master
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop-slave-1
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop-slave-2
chmod 0600 ~/.ssh/authorized_keys
exit
|
五、下载Hadoop
这里使用Hadoop的一个稳定点的版本2.7.3
1
2
3
4
5
6
7
| mkdir /opt/hadoop
cd /opt/hadoop/
wget http://apache.mesi.com.ar/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
tar -xzf hadoop-2.7.3.tar.gz
mv hadoop-2.7.3 hadoop
chown -R hadoop /opt/hadoop
cd /opt/hadoop/hadoop/
|
六、配置Hadoop
1.修改core-site.xml
在标签中间添加下面内容
1
2
3
4
5
6
7
8
| <property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
|
2.修改hdfs-site.xml
在标签中间添加下面内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
|
3.修改 mapred-site.xml
首先先运行下面命令
1
| cp mapred-site.xml.template mapred-site.xml
|
然后在标签中间添加下面内容
1
2
3
4
| <property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
|
4.修改hadoop-env.sh
1
2
3
| export JAVA_HOME=/opt/jdk1.7.0_79
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/conf
|
你的Java路径
七、复制Hadoop到子节点
利用SSH复制,速度有点慢,喝杯茶等一下
1
2
3
4
| su hadoop
cd /opt/hadoop
scp -r hadoop hadoop-slave-1:/opt/hadoop
scp -r hadoop hadoop-slave-2:/opt/hadoop
|
八、配置Hadoop(只在master上进行)
先进入Hadoop路径
1
2
| su hadoop
cd /opt/hadoop/hadoop
|
1.修改conf/masters
2.修改conf/slaves
1
2
| hadoop-slave-1
hadoop-slave-2
|
九、在master上格式化namenode
1
2
3
| su hadoop
cd /opt/hadoop/hadoop
bin/hadoop namenode -format
|
十、开启Hadoop服务
使用下面命令,直接启动所有服务
相关推荐
基于OGG的Oracle与Hadoop集群准实时同步介绍
【腾讯云的1001种玩法】hadoop伪分布式搭建

